How I Created A Financial Dataset And Trained BERT On It
Published 7.3.2024
Table of contents
Introduction
For my bachelor thesis, I wanted to create a dataset of sentences from Yahoo Finance news articles and train a pre-trained BERT model on it. In this post I will explain all the steps I took to create the dataset and train the model.
How I created the dataset
Extracting the articles HTML
First, I decided to use only articles in the Business category.
Second, I analysed the HTML structure of a Yahoo Finance news article page. I found that the article text was inside a div with the class “caas-body”.
<div class="caas-body">...</div>
Inside this div there are multiple p tags that contain the sentences of the article like:
<p>
The Icheon-based firm is investing more than $1 billion in South Korea to expand and improve the
final steps of its chip manufacture, said Lee Kang-Wook, a former Samsung Electronics Co. engineer
who now heads up packaging development at SK Hynix. Innovation with that process is at the heart
of HBM’s advantage as the most sought-after AI memory, and further advances will be key to
reducing power consumption, driving performance and cementing the company’s lead in the HBM
market.
</p>
I then started to create a notebook to scrape the text from the articles and store it in a SQLite database. For the scraping part, I used the BeautifulSoup library. The following code snippets will explain how I did it:
res = requests.get(link) # link is the URL of the article
soup = BeautifulSoup(res.text, "html.parser") # res.text is the HTML of the article
# store the title in a variable to save it in the database
title = soup.find("title").text
# The title Yahoo is returned on the html, when a 404 error occurs
if(soup == None or title == 'Yahoo'):
continue
# get the div with the class caas-body
soup = soup.find("div", attrs={'class':'caas-body'})
for div in soup.find_all('div'):
div.unwrap() # remove all div tags
for ul in soup.find_all('ul'):
p_tag = ul.find_previous_sibling('p') # get the p tag before the ul tag
if p_tag:
p_tag.decompose() # remove the p tag
# remove all ul tags (these are usually lists of links to other articles)
for ul in soup.find_all("ul"):
ul.decompose()
for button in soup.find_all("button"):
button.decompose() # remove all button tags
for p_tag in soup.find_all('p', string="©2023 Bloomberg L.P."):
p_tag.decompose() # remove the p tag with the copyright text
text = ""
for p in soup.find_all('p'):
text = text + p.text + "\n"
This scraping script is very rudimentary and only works for the specific HTML structure of Yahoo Finance news articles. For example, it will not work on articles that contain images or videos. It is also not able to extract just the useful sentences from the articles because they are so dynamic in their structure. But it was good enough for my purposes.
Extracting all available links from the news page
Now I needed to find a way to automate the scraping of link articles to feed this script. I used the Selenium library to automate this process. I created another notebook that opens a Chrome browser, scrolls down on the cookie modal, clicks deny, then scrolls down to the bottom of the page to load more articles. It then extracts the HTML from the page. Once this is done, BeautifulSoup is used to extract the links from the articles and store them in a list. This list is then used to feed the scraping script.
This code opens a Chrome browser and gets the HTML of the Yahoo Finance news page:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
import time
# Initialisiere den WebDriver
driver = webdriver.Chrome()
# Navigiere zur Webseite
driver.get("https://finance.yahoo.com/news")
# Ablehnen des Cookie Popups
scroll_button = driver.find_element(By.ID, "scroll-down-btn")
scroll_button.click()
cookie_button = driver.find_element(By.CLASS_NAME, "reject-all")
cookie_button.click()
html_element = driver.find_element(By.TAG_NAME, 'html')
# Drücke 16 Mal die "End"-Taste
for _ in range(16):
html_element.send_keys(Keys.END)
time.sleep(1)
# Hole das HTML der Seite
html = driver.page_source
# Schließe den Browser
driver.quit()
After that the following script saves the links from the HTML to a file:
# Verwende BeautifulSoup, um das HTML zu parsen
soup = BeautifulSoup(html, 'html.parser')
# Finde alle Artikel
articles = soup.find_all('li', class_='js-stream-content Pos(r)')
business_articles = []
# Überprüfe, ob das li ein div mit Inhalt "Business" hat und behalte nur diese
for article in articles:
bsn = article.find_all('div', string='Business')
if bsn:
business_articles.append(article)
links = []
# Extrahiere den Link zum Artikel
for article in business_articles:
link = article.find('a')
# Füge finance.yahoo.com vorne an
link = 'https://finance.yahoo.com' + link['href']
links.append(link)
# Füge die Links in eine Datei ein
with open('links.txt', 'a') as f:
for link in links:
f.write(link + '\n')
Now that I had the links in a file, I could use the scraping script from before and just loop over all the links to scrape the text of each article and store it in the database.
Splitting the text into sentences
This was the first step in the process. The second step was to split the text into individual sentences, save them in another table and then use three BERT models (FinancialBERT, FinBERT and DistilRoBERTa) to classify each sentence into one of the following categories: “bullish”, “bearish” or “neutral”. Each model was trained on a different pre-trained BERT model and fine-tuned on the financial_phrasebank dataset.
For the sentence extraction part there exist libraries like NLTK but I found a little script that uses regular expressions and neat little tricks to do a better job:
alphabets= "([A-Za-z])"
prefixes = "(Mr|St|Mrs|Ms|Dr)[.]"
suffixes = "(Inc|Ltd|Jr|Sr|Co)"
starters = "(Mr|Mrs|Ms|Dr|Prof|Capt|Cpt|Lt|He\s|She\s|It\s|They\s|Their\s|Our\s|We\s|But\s|However\s|That\s|This\s|Wherever)"
acronyms = "([A-Z][.][A-Z][.](?:[A-Z][.])?)"
websites = "[.](com|net|org|io|gov|edu|me)"
digits = "([0-9])"
multiple_dots = r'\.{2,}'
def remove_author_notes(text):
# Broaden pattern to match updates or other notes at the beginning
text = re.sub(r'^\([^\)]+\)\s*', '', text)
# Pattern to match author and location, updated to handle variations
text = re.sub(r'By\s.+?\s\(.+?\)\s*[-–]\s*', '', text)
# Pattern to match Month Day () -
text = re.sub(r'\w{3}\s\d{1,2}\s\([^)]*\)\s*-\s*', '', text)
# Pattern to match additional reporting or editing notes at the end, updated for flexibility
text = re.sub(r'\(Reporting by [\w\s,]+;\s*additional reporting by [\w\s,]+;\s*Editing by [\w\s,]+\)$', '', text, flags=re.IGNORECASE)
return text
# https://stackoverflow.com/a/31505798 (source)
def split_into_sentences(text: str) -> list[str]:
"""
Split the text into sentences.
If the text contains substrings "<prd>" or "<stop>", they would lead
to incorrect splitting because they are used as markers for splitting.
:param text: text to be split into sentences
:type text: str
:return: list of sentences
:rtype: list[str]
"""
text = " " + text + " "
text = text.replace("\n"," ")
text = re.sub(prefixes,"\\1<prd>",text)
text = re.sub(websites,"<prd>\\1",text)
text = re.sub(digits + "[.]" + digits,"\\1<prd>\\2",text)
text = re.sub(multiple_dots, lambda match: "<prd>" * len(match.group(0)) + "<stop>", text)
if "Ph.D" in text: text = text.replace("Ph.D.","Ph<prd>D<prd>")
if "No." in text: text = text.replace("No.","No<prd>")
if "Jan." in text: text = text.replace("Jan.","Jan<prd>")
if "Feb." in text: text = text.replace("Feb.","Feb<prd>")
if "Mar." in text: text = text.replace("Mar.","Mar<prd>")
if "Apr." in text: text = text.replace("Apr.","Apr<prd>")
if "Jun." in text: text = text.replace("Jun.","Jun<prd>")
if "Jul." in text: text = text.replace("Jul.","Jul<prd>")
if "Aug." in text: text = text.replace("Aug.","Aug<prd>")
if "Sep." in text: text = text.replace("Sep.","Sep<prd>")
if "Sept." in text: text = text.replace("Sept.","Sept<prd>")
if "Oct." in text: text = text.replace("Oct.","Oct<prd>")
if "Nov." in text: text = text.replace("Nov.","Nov<prd>")
if "Dec." in text: text = text.replace("Dec.","Dec<prd>")
if "Corp." in text: text = text.replace("Corp.","Corp<prd>")
if "Ltd." in text: text = text.replace("Ltd.","Ltd<prd>")
if "vs." in text: text = text.replace("vs.","vs<prd>")
if "e.g." in text: text = text.replace("e.g.","e<prd>g<prd>")
if "i.e." in text: text = text.replace("i.e.","i<prd>e<prd>")
if "Sen." in text: text = text.replace("Sen.","Sen<prd>")
if "Calif." in text: text = text.replace("Calif.","Calif<prd>")
if "Gov." in text: text = text.replace("Gov.","Gov<prd>")
text = re.sub("\s" + alphabets + "[.] "," \\1<prd> ",text)
text = re.sub(acronyms+" "+starters,"\\1<stop> \\2",text)
text = re.sub(alphabets + "[.]" + alphabets + "[.]" + alphabets + "[.]","\\1<prd>\\2<prd>\\3<prd>",text)
text = re.sub(alphabets + "[.]" + alphabets + "[.]","\\1<prd>\\2<prd>",text)
text = re.sub(" "+suffixes+"[.] "+starters," \\1<stop> \\2",text)
text = re.sub(" "+suffixes+"[.]"," \\1<prd>",text)
text = re.sub(" " + alphabets + "[.]"," \\1<prd>",text)
if "”" in text: text = text.replace(".”","”.")
if "\"" in text: text = text.replace(".\"","\".")
if "!" in text: text = text.replace("!\"","\"!")
if "?" in text: text = text.replace("?\"","\"?")
text = text.replace(".",".<stop>")
text = text.replace("?","?<stop>")
text = text.replace("!","!<stop>")
text = text.replace("<prd>",".")
text = text.replace('<ellipsis>', '...')
text = text.replace('<qst>', '?')
text = text.replace('<exc>', '!')
sentences = text.split("<stop>")
sentences = [s.strip() for s in sentences]
if sentences and not sentences[-1]: sentences = sentences[:-1]
return sentences
def remove_parenthetical_sentences(sentences):
cleaned_sentences = []
for sentence in sentences:
# Check if the entire sentence is within parentheses
if sentence.startswith('(') and sentence.endswith(')'):
continue # Skip this sentence
cleaned_sentences.append(sentence)
return cleaned_sentences
def merge_parenthetical_statements(text):
# Replace periods within parentheses with a placeholder
text = re.sub(r'\(([^)]+)\)', lambda m: "(" + m.group(1).replace('.', '<prd>') + ")", text)
return text
def replace_ellipses(text):
# Replace '...' with a placeholder
return re.sub(r'\.\.\.', '<ellipsis>', text)
def replace_sentence_stops_in_quotes(text):
# Define a function to replace sentence stops within a matched quote
def replace_stops(match):
# Replace all periods, question marks, and exclamation marks in the matched quote
temp = match.group(0).replace('.', '<prd>')
temp = temp.replace('?', '<qst>')
temp = temp.replace('!', '<exc>')
return temp
# Regex-Muster, das Text in Anführungszeichen erfasst
quote_pattern = r'["“”](.*?)["“”]'
# ersetzte alle Satzzeichen in Anführungszeichen
text = re.sub(quote_pattern, replace_stops, text, flags=re.UNICODE)
return text
With a little tweaking, this script was able to split the text into sentences the way I wanted. Once the sentences were split, they were stored in a table called sentences in the database.
Classifying the sentences
The following script, gets all sentences, classifies them with the selected model and then saves the classification to the database:
from transformers import AutoModelForSequenceClassification, AutoTokenizer
import torch
# ProsusAI/finbert
# mrm8488/distilroberta-finetuned-financial-news-sentiment-analysis
# Sigma/financial-sentiment-analysis
model_name = "ProsusAI/finbert"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)
# get each row from senteces table in sentiment.db sqlite
import sqlite3
conn = sqlite3.connect("data/sentiment.db")
c = conn.cursor()
c.execute("SELECT * FROM sentences WHERE finbert_result != 'bullish'")
rows = c.fetchall()
for row in rows:
id = row[0]
sentence_text = row[2]
inputs = tokenizer(sentence_text, return_tensors="pt", padding=True, truncation=True, max_length=512)
# Wende das Modell an
with torch.no_grad():
outputs = model(**inputs)
# Hole die Modellvorhersagen
predictions = outputs.logits
# Konvertiere Vorhersagen in Wahrscheinlichkeiten und hole das maximale
predictions = torch.nn.functional.softmax(predictions, dim=1)
predicted_class = torch.argmax(predictions).item()
# behalte die Wahrscheinlichkeit für die Vorhersage
predicted_probability = predictions.flatten()[predicted_class].item()
# CLASSES ARE DIFFERENT FOR FINBERT
classesFINBERT = ["bullish", "bearish", "neutral"]
classes = ["bearish", "neutral", "bullish"]
# print(f"Class: {classesFINBERT[predicted_class]}, Probability: {predicted_probability:.3f}")
# update _result and _score column for each model but only take 3 decimals for _score
c.execute("UPDATE sentences SET finbert_result = ?, finbert_score = ? WHERE id = ?", (classesFINBERT[predicted_class], round(predicted_probability, 3), id))
if(id % 100 == 0):
print(id)
conn.commit()
conn.close()
Manual classification of sentences
Some sentences could not be classified with the majority of points from the models. For these sentences I wanted to classify them manually. I wrote a small Python application that showed all the sentences marked for manual classification and also gave me the scores of the models for each sentence. I then classified each sentence and saved the result to the database.

Training the BERT model
For the training part I used the FinancialBERT pre-trained Model from ahmedrachid because it was pre-trained on a large corpus of financial texts such as:
- TRC2-financial: 1.8M news articles that were published by Reuters between 2008 and 2010.
- Bloomberg News: 400,000 articles between 2006 and 2013.
- Corporate Reports: 192,000 transcripts (10-K & 10-Q)
- Earning Calls: 42,156 documents.
This seemed the smarter choice for my purpose, rather than using the standard BERT base model.
The following sections will all explain the training process in detail.
Preparing the dataset
Before I started training, I had to prepare the dataset for the model to work with. For that, I extracted all the sentences and their classification from my SQLite database. The cell below from my notebook shows this first step:
import sqlite3
from sklearn.model_selection import train_test_split
# Connect to the database
conn = sqlite3.connect('data/sentiment.db')
cursor = conn.cursor()
# Fetch the data from the "sentences" table
cursor.execute("SELECT sentence_text, final_sentiment FROM sentences WHERE final_sentiment != 'manual'")
data = cursor.fetchall()
# Close the database connection
conn.close()
# Convert data to a dictionary with the keys "text" and "label"
data = [{"text": text, "label": label} for text, label in data]
# Convert bullish to 0, neutral to 1, and bearish to 2
# data = [{"text": row["text"], "label": 0 if row["label"] == "bullish" else 1 if row["label"] == "neutral" else 2} for row in data]
data = [{"text": row["text"], "label": 0 if row["label"] == "bearish" else 1 if row["label"] == "neutral" else 2} for row in data]
# Split the data into train, test, and validation sets
train_data, test_data = train_test_split(data, test_size=0.15, random_state=42)
train_data, val_data = train_test_split(train_data, test_size=0.15, random_state=42)
# Print the sizes of the train, test, and validation sets
print("Train data percentage:", (round((len(train_data) / len(data)) * 100)))
print("Test data percentage:", (round((len(test_data) / len(data)) * 100)))
print("Validation data percentage:", (round((len(val_data) / len(data)) * 100)))
Because I saved the classifiactions in text form, I had to convert them to numbers first. After that I split the data into training, test and validation sets.
Tokenizing the dataset
After preparing the dataset, the sentences and their labels had to be tokenized so the model could work with them. The following code snippet shows how this was done:
from transformers import AutoTokenizer
import torch
# Lade den Tokenizer
# model_name = 'ahmedrachid/FinancialBERT'
model_name = 'ahmedrachid/FinancialBERT-Sentiment-Analysis'
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Funktion, um die Daten zu tokenisieren
def tokenize_data(data):
tokenized_data = []
for item in data:
# Tokenisiere den Text und füge das Ergebnis dem Array hinzu
encoding = tokenizer(
item['text'],
padding='max_length', # Pad kürzere Sätze
truncation=True, # Schneide längere Sätze ab
max_length=512, # Maximale Länge auf BERT's limit setzen
return_tensors='pt' # Rückgabe als PyTorch Tensoren
)
tokenized_data.append({'input_ids': encoding['input_ids'].squeeze(0), 'attention_mask': encoding['attention_mask'].squeeze(0), 'label': item['label']})
return tokenized_data
# Tokenisiere Trainings-, Test- und Validierungsdaten
train_data_tokenized = tokenize_data(train_data)
val_data_tokenized = tokenize_data(val_data)
test_data_tokenized = tokenize_data(test_data)
After this I had to convert the tokenized data to PyTorch datasets and also set a batch size for the training process. For my case I chose a batch size of 16 because I was training on a NVIDIA GeForce RTX 2080 Ti with 11 GB of VRAM.
Training the model
The following code snippet shows how the training was done:
from transformers import BertForSequenceClassification, get_linear_schedule_with_warmup, get_cosine_schedule_with_warmup
import torch.optim as optim
import json
from sklearn.metrics import f1_score
from tqdm.auto import tqdm
import datetime
metrics = {
'batch': [],
'train_loss': [],
'val_loss': [],
'f1': [],
'lr': []
}
# Füge diese Funktion hinzu, um die Validierungsleistung zu bewerten
def evaluate(model, val_loader, device):
model.eval() # Setze das Modell in den Evaluierungsmodus
total_eval_loss = 0
# Listen für wahre Labels und Vorhersagen
true_labels = []
predictions = []
for batch in val_loader:
# Übertrage die Batch-Daten auf das richtige Device (z.B. GPU)
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['label'].to(device)
with torch.no_grad(): # Deaktiviere die Gradientenberechnung für die Evaluation
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
total_eval_loss += loss.item()
# Berechne Vorhersagen
logits = outputs.logits
preds = torch.argmax(logits, dim=-1)
# Sammle wahre Labels und Vorhersagen für Metrikberechnung
predictions.extend(preds.cpu().numpy())
true_labels.extend(labels.cpu().numpy())
f1 = f1_score(true_labels, predictions, average='weighted')
return total_eval_loss / len(val_loader), f1 # Gib Durchschnittsverlust und Metriken zurück
# Funktion zum Aktualisieren der Metriken nach jeder Epoche
def update_metrics(batch, train_loss, val_loss, f1, lr):
metrics['batch'].append(batch)
metrics['train_loss'].append(train_loss)
metrics['val_loss'].append(val_loss)
metrics['f1'].append(f1)
metrics['lr'].append(lr)
# id2label = {0: 'bullish', 1: 'neutral', 2: 'bearish'}
# label2id = {'bullish': 0, 'neutral': 1, 'bearish': 2}
id2label = {0: 'bearish', 1: 'neutral', 2: 'bullish'}
label2id = {'bearish': 0, 'neutral': 1, 'bullish': 2}
# Modell laden
# model = BertForSequenceClassification.from_pretrained('ahmedrachid/FinancialBERT', num_labels=3, id2label=id2label, label2id=label2id) # Angenommene 3 Labels: bullish, neutral, bearish
# model = BertForSequenceClassification.from_pretrained('ahmedrachid/FinancialBERT-Sentiment-Analysis', num_labels=3, id2label=id2label, label2id=label2id,config=configuration) # Angenommene 3 Labels: bullish, neutral, bearish
model = BertForSequenceClassification.from_pretrained('ahmedrachid/FinancialBERT-Sentiment-Analysis', num_labels=3, id2label=id2label, label2id=label2id, hidden_dropout_prob=0.3)
# Überprüfen, ob CUDA verfügbar ist und eine GPU zuweisen
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device) # Modell auf die GPU verschieben
num_epochs = 3
learning_rate = 2e-5 # 2e-5
weight_decay = 0.01 # 0.0001
current_time = datetime.datetime.now().strftime("%Y%m%d-%H%M%S") # Timestamp to avoid overwriting
# Optimierer definieren
optimizer = optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay)
# optimizer = optim.AdamW(model.parameters(), lr=learning_rate)
# Gesamte Trainingssteps und Warm-Up Steps definieren
total_steps = len(train_loader) * num_epochs # Gesamte Anzahl von Trainingsschritten
warmup_steps = int(total_steps * 0.1) # 10% der Trainingsschritte als Warm-Up
# Scheduler initialisieren
# scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=warmup_steps, num_training_steps=total_steps)
# scheduler = get_cosine_schedule_with_warmup(optimizer, num_warmup_steps=warmup_steps, num_training_steps=total_steps)
logging_interval = 200 # Logge die Metriken alle 100 Batches
# Create a directory name with hyperparameters
dir_name = f"model_epoch{num_epochs}_lr{learning_rate}_bs{batch_size}_withFinancialPhrasebank_withDropout03_nullGradientFirst_{current_time}"
# Specify the base path where you want to save the models
base_path = "models/financial_phrasebank_test/"
# Full path
save_path = base_path + dir_name
global_batch = 0
for epoch in range(num_epochs): # num_epochs ist die Anzahl der Epochen, die du trainieren möchtest
# Progress bar with tqdm
progress_bar = tqdm(enumerate(train_loader), desc=f"Epoch {epoch + 1}/{num_epochs}", total=len(train_loader), unit="batch")
for batch in train_loader:
model.train() # Setze das Modell wieder in den Trainingsmodus
# Extrahiere Daten aus dem Batch
input_ids = batch['input_ids'].to(device) # Übertrage die Eingabedaten auf das richtige Device (z.B. GPU)
attention_mask = batch['attention_mask'].to(device) # Maske für padding
labels = batch['label'].to(device) # Stelle sicher, dass deine Labels als Tensor von numerischen Labels vorliegen
# Null the gradients
optimizer.zero_grad()
# Forward pass
outputs = model(input_ids, attention_mask=attention_mask, labels=labels) # Führe die Vorwärtsdurchläufe durch
loss = outputs.loss # Verlust berechnen
# Backward pass
loss.backward() # Berechne die Gradienten
optimizer.step() # Aktualisiere die Parameter und berechne die nächsten Gradienten
# scheduler.step()
# optimizer.zero_grad() # Null die Gradienten aus, damit sie nicht akkumuliert werden
# Update the progress bar
progress_bar.set_postfix(loss=loss.item())
progress_bar.update()
if global_batch % logging_interval == 0 and global_batch != 0:
# Evaluate the model on the validation set
val_loss, f1 = evaluate(model, val_loader, device)
update_metrics(global_batch, loss.item(), val_loss, f1, learning_rate) # scheduler.get_last_lr()[0]
print(f"Step: {global_batch}, Learning Rate {learning_rate}, Validation loss: {val_loss:.3f}, Train loss: {loss.item():.3f}, F1: {f1:.3f}")
global_batch += 1
# Save the model after each epoch
epoch_save_path = f"{save_path}/epoch_{epoch+1}"
model.save_pretrained(epoch_save_path)
with open(f'{save_path}/metrics.json', 'w') as f:
json.dump(metrics, f)
To summarise this snippet, I first loaded the model and set the device to the GPU. Then I defined the optimiser and the scheduler. Then I started the training loop. In the loop I first set the model to training mode and then extracted the data from the batch. Then I set the gradients to zero, did a forward pass, calculated the loss, did a backward pass and updated the parameters. I then evaluated the model on the validation set and updated the metrics. At the end of each epoch I saved the model and the metrics.
Evaluation
After the training process I evaluated the model on the test set. The following data shows the results:
- Test Loss: 0.21471
- Accuracy: 0.925752
- F1-Score: 0.925923
- Precision: 0.92701
- Recall: 0.925752
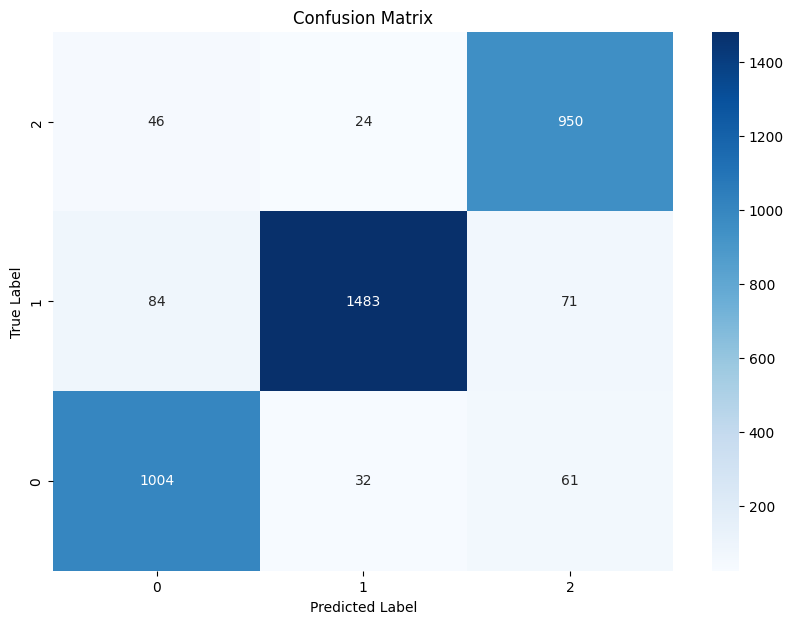
| precision | recall | f1 | support | |
|---|---|---|---|---|
| bullish | 0.89 | 0.92 | 0.90 | 1097 |
| neutral | 0.96 | 0.91 | 0.93 | 1638 |
| bearish | 0.88 | 0.93 | 0.90 | 1020 |
| accuracy | 0.92 | 3755 | ||
| macro avg | 0.91 | 0.92 | 0.91 | 3755 |
| weighted avg | 0.92 | 0.92 | 0.92 | 3755 |
Even though the training data was not perfect I managed to achieve an accuracy of 92.6% on the test set. This is a very good result for my purpose.
Conclusion
This project was very interesting and I learnt a lot from it. I was able to create a dataset of financial sentences and train a pre-trained BERT model on it. The model was able to classify the sentences into the categories “bullish”, “bearish” and “neutral” with an accuracy of 92.6%. I also learned a lot about the BERT model and how to train it. I am very happy with the results and look forward to using the model in my bachelor thesis.